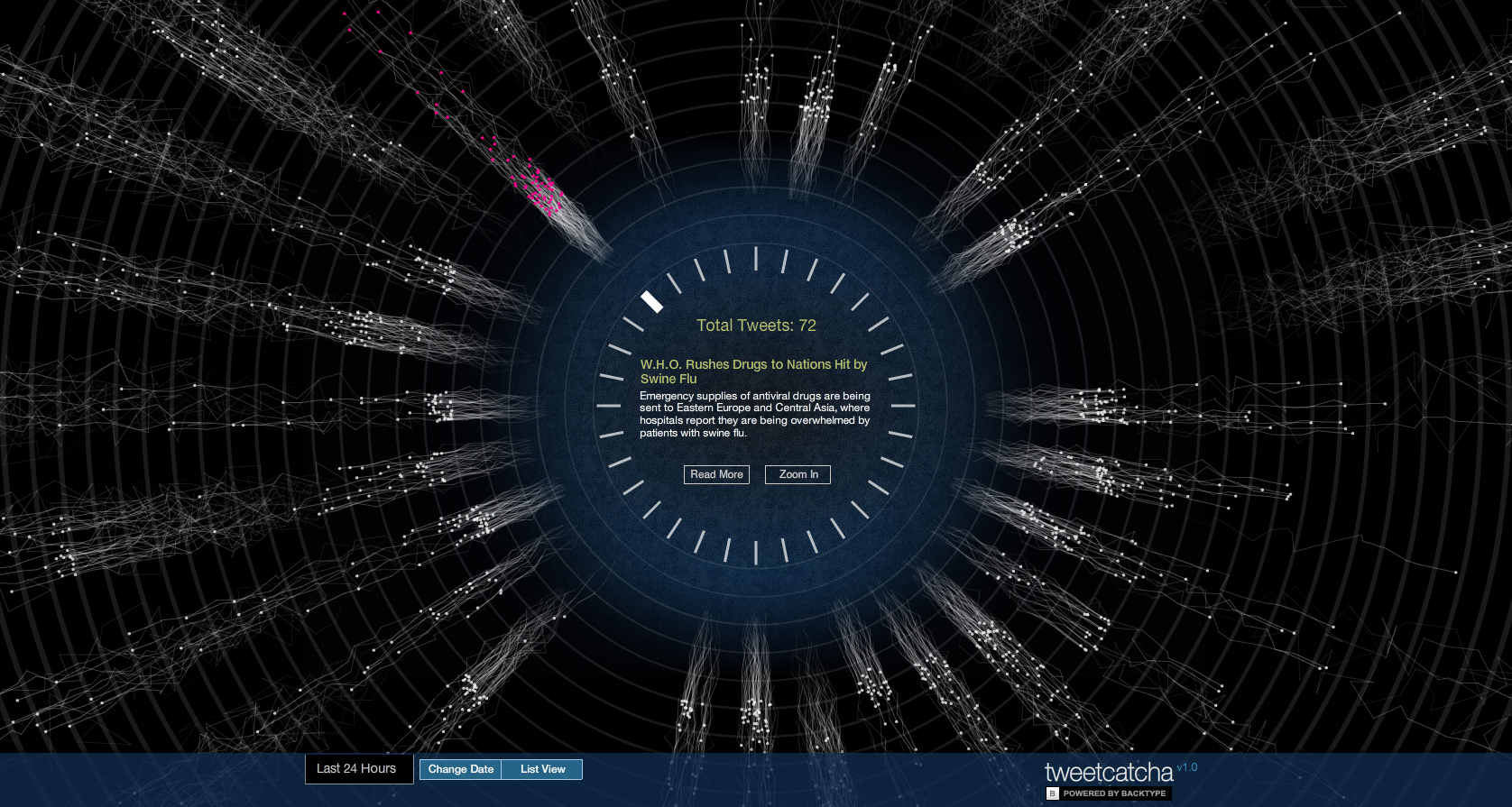
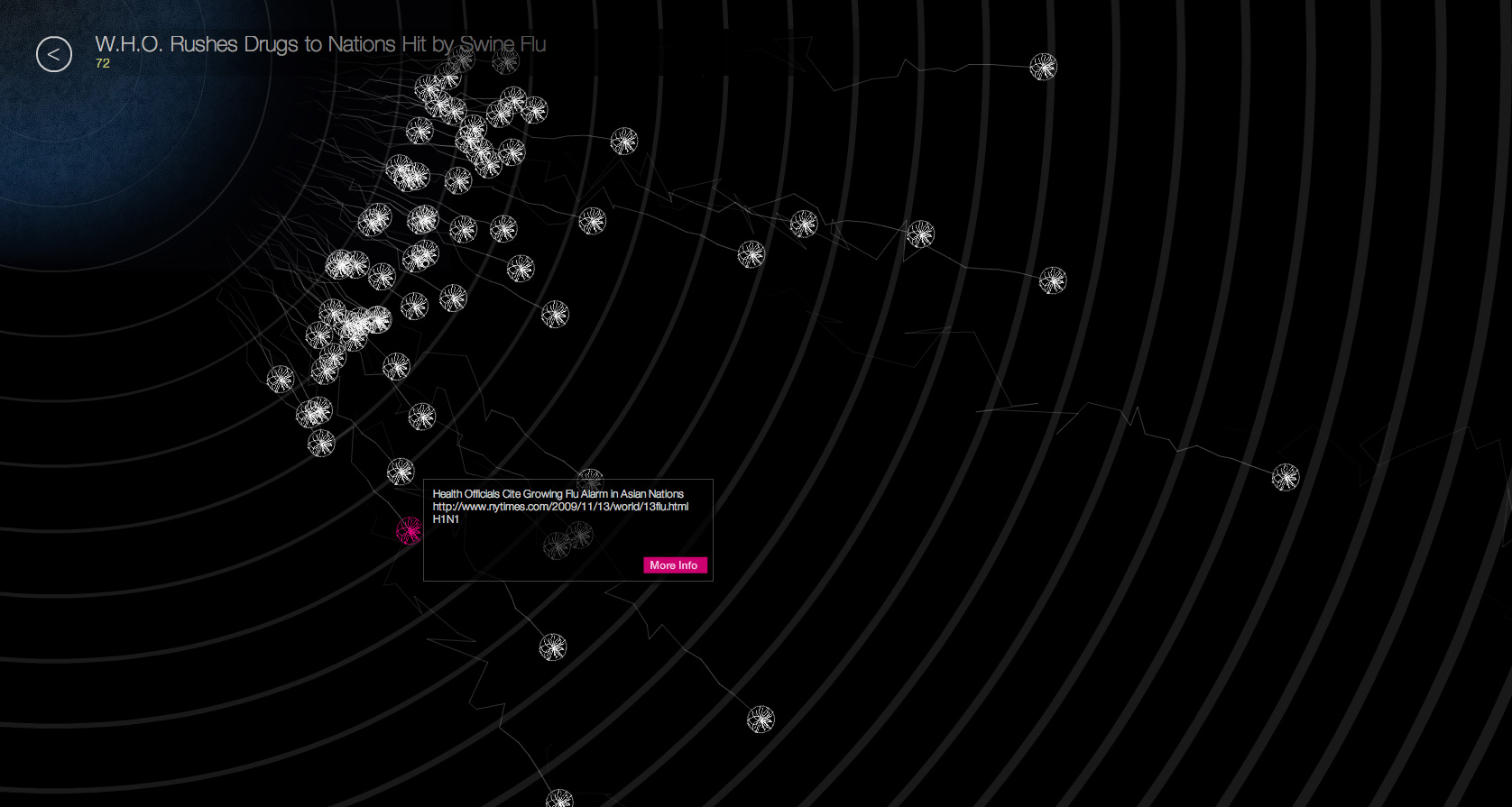
TweetCatcha seeks to uncover the organic nature of news as it travels through Twitter over time, by examining the movement of NY Times articles through Twitter.
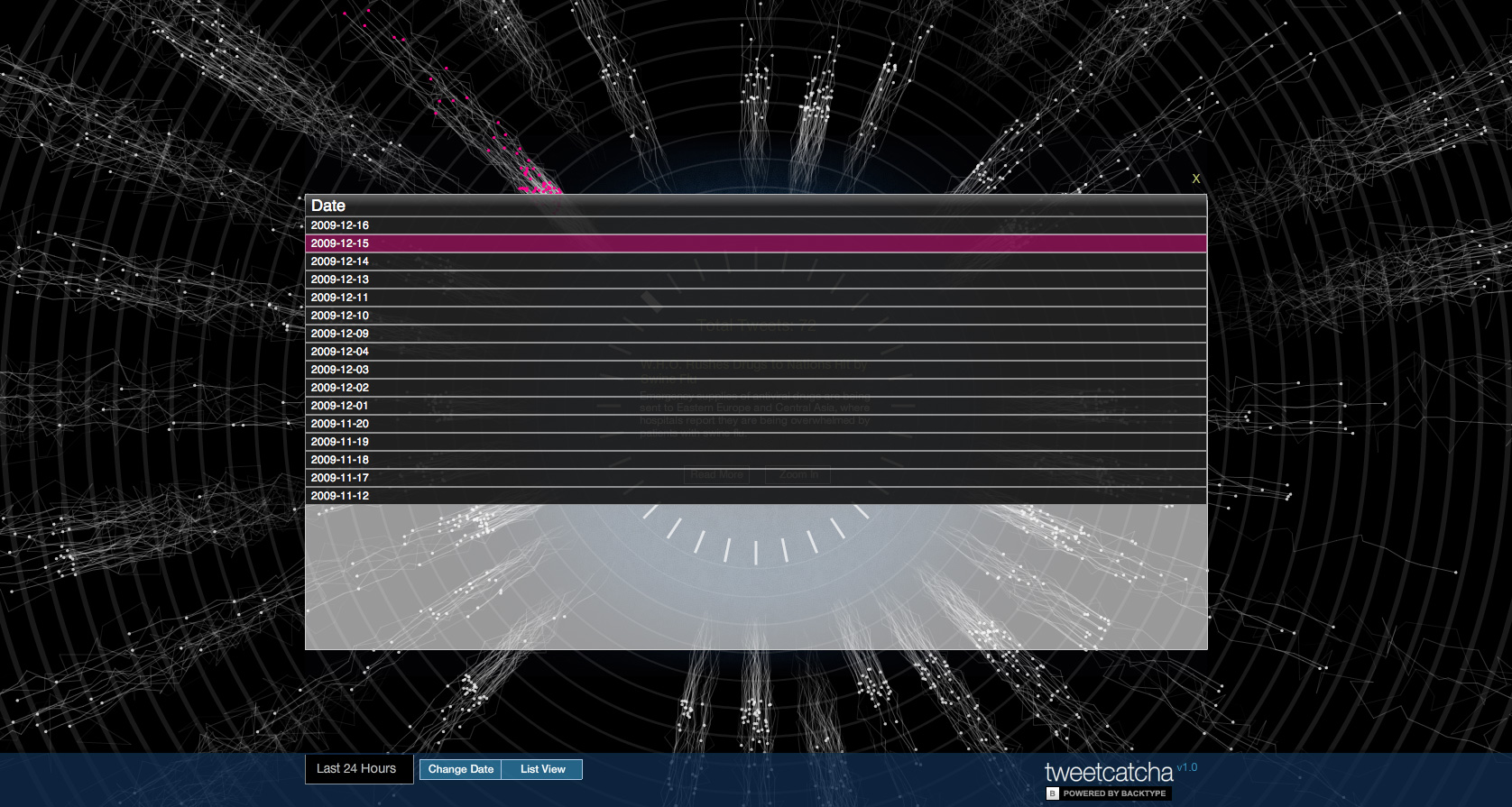
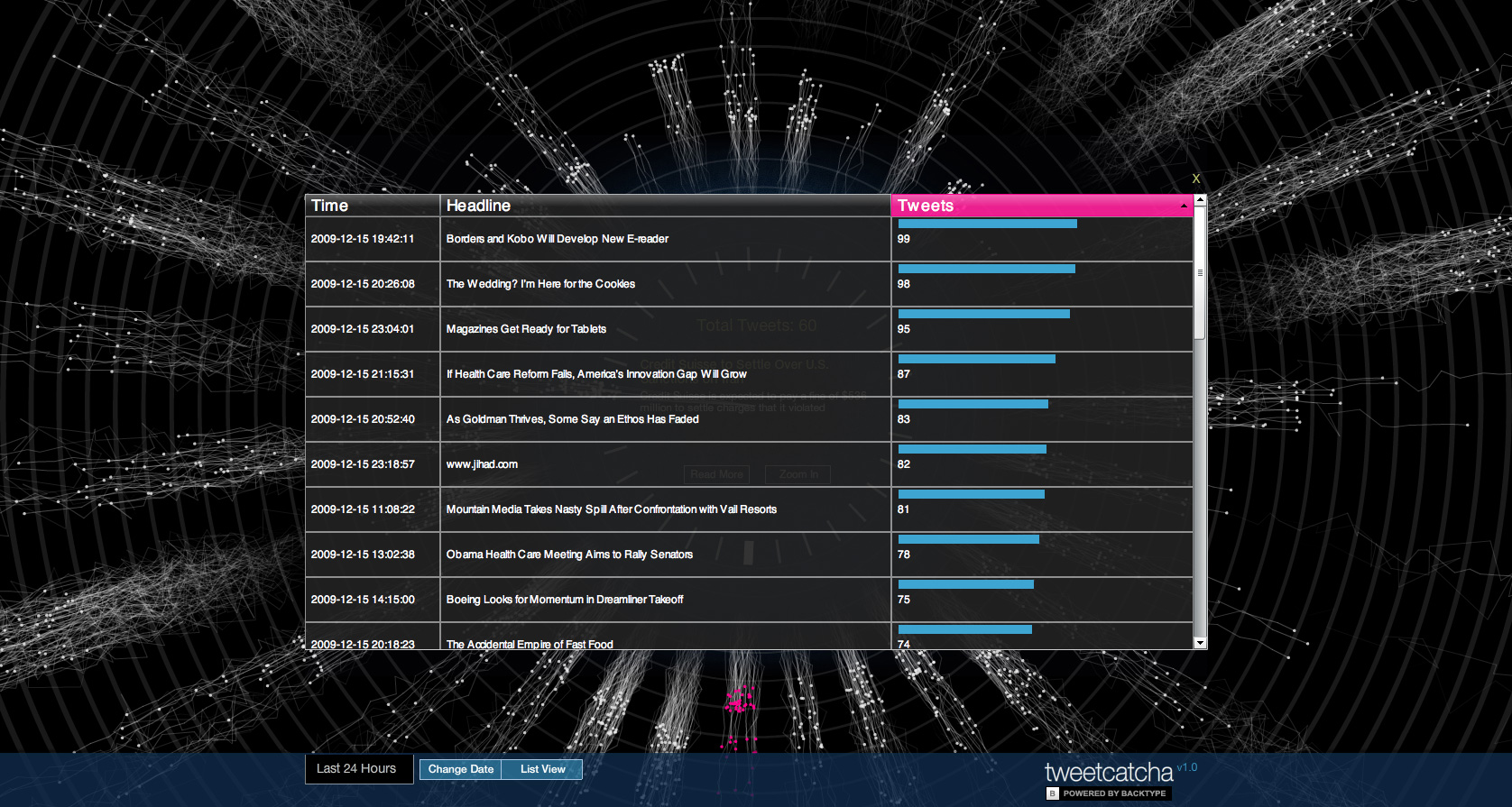
The New York Times Newswire API is used to load news for the last 24 hours. The title and URL for the retrieved articles are used to search for tweets with the BackTweets API, a BackType service.
The articles are placed around the center arranged clockwise based on the time they were published. The tweets for each article emanate from the article near the center to the outside. These are based on the time difference between when the article was published and when it was tweeted. The 24 rings indicate the hour difference from 1 near the center to 24 near the outside.
This project was built with ActionScript 3, PHP, MySQL, XML. The data was harvested using the NY Timeswire API and backtweets API.
Data was collected between November 13, 2009 and February 9, 2010 via a cron job set up to pull and store the data locally. The current database is 107 MB, with 15,327 NYTimes articles and 311,885 tweets for those articles.